Начало работы
![]()
Добро пожаловать в книгу "Асинхронное программирование в Rust"! Если вы собираетесь начать писать асинхронный код на Rust, вы находитесь в правильном месте. Строите ли вы веб-сервер, базу данных или операционную систему, эта книга покажет вам как использовать инструменты асинхронного программирования, чтобы получить максимальную отдачу от вашего оборудования.
Что охватывает эта книга?
Эта книга призвана стать исчерпывающим, современным руководством по использованию асинхронных языковых возможностей и библиотек Rust, подходящим как новичкам, так и опытным разработчикам.
-
Ранние главы содержат введение в асинхронное программирование в целом, а также его особенности в Rust.
-
В средних главах обсуждаются ключевые утилиты и инструменты управления потоком, которые вы можете использовать, когда пишете асинхронный код. Также здесь описаны лучшие практики структурирования библиотек и приложений для получения максимальной производительности и повторного использования кода.
-
Последняя глава книги покрывает асинхронную экосистему и предоставляет ряд примеров того, как можно выполнить общие задачи.
Итак, давайте исследуем захватывающий мир асинхронного программирования в Rust!
Для чего нужна асинхронность?
Нам всем нравится, как Rust позволяет нам писать быстрое и безопасное программное обеспечение. Но как асинхронное программирование вписывается в это видение?
Асинхронное программирование, или сокращённо async, — это параллельная модель программирования, поддерживаемая растущим числом языков программирования. Он позволяет выполнять большое количество одновременных задач в небольшом количестве потоков ОС, сохраняя при этом большую часть внешнего вида обычного синхронного программирования с помощью синтаксиса async/await.
Асинхронность и другие модели параллелизма
Параллельное программирование менее развито и «стандартизировано», чем обычное последовательное программирование. В результате мы по-разному выражаем параллелизм в зависимости от того, какую модель параллельного программирования поддерживает язык. Краткий обзор самых популярных моделей параллелизма поможет вам понять, как асинхронное программирование вписывается в более широкую область параллельного программирования:
- Потоки ОС не требуют каких-либо изменений в модели программирования, что упрощает реализацию параллелизма. Однако синхронизация между потоками может быть затруднена, а издержки производительности велики. Пулы потоков могут снизить некоторые из этих затрат, но не настолько, чтобы поддерживать огромные рабочие нагрузки, связанные с вводом-выводом.
- Программирование, управляемое событиями (event-driven programming), в сочетании с обратными вызовами (callbacks) может быть очень эффективным, но приводит к многословному, «нелинейному» потоку управления. Поток данных и распространение ошибок часто трудно отслеживать.
- Корутины (Coroutines), как и потоки, не требуют изменений в модели программирования, что делает их простыми в использовании. Как и асинхронность, они также могут поддерживать большое количество задач. Однако они абстрагируются от низкоуровневых деталей, важных для системного программирования и разработчиков пользовательских сред выполнения.
- Модель акторов делит все параллельные вычисления на единицы, называемые акторами, которые взаимодействуют посредством передачи ошибочных сообщений, как в распределённых системах. Модель акторов может быть эффективно реализована, но она оставляет без ответа многие практические вопросы, такие как управление потоком и логика повторных попыток.
Таким образом, асинхронное программирование допускает высокопроизводительные реализации, подходящие для низкоуровневых языков, таких как Rust, и в то же время обеспечивает большинство эргономических преимуществ потоков и корутин.
Асинхронность в Rust против других языков
Хотя асинхронное программирование поддерживается на многих языках, некоторые детали зависят от реализации. Реализация асинхронности в Rust отличается от большинства языков несколькими способами:
- Футуры инертны в Rust и работают только при опросе. Сбрасывание футуры останавливает её дальнейший прогресс.
- Асинхронность в Rust бесплатна (zero-cost), а это значит, что вы платите только за то, что используете. В частности, вы можете использовать асинхронность без распределения кучи и динамической диспетчеризации, что отлично подходит для производительности! Это также позволяет использовать асинхронность в средах с ограничениями, таких как встроенные системы.
- В Rust нет встроенной среды выполнения асинхронности. Вместо этого такие среды предоставляются трейтами, поддерживаемыми сообществом.
- В Rust доступны как однопоточные, так и многопоточные среды выполнения, которые имеют разные сильные и слабые стороны.
Асинхронность против потоков в Rust
Основной альтернативой асинхронности в Rust является использование потоков ОС либо напрямую через std::thread, либо косвенно через пул потоков. Переход от потоков к асинхронному или наоборот обычно требует серьёзной работы по рефакторингу как с точки зрения реализации, так и (если вы создаёте библиотеку) любых открытых общедоступных интерфейсов. Таким образом, ранний выбор модели, которая соответствует вашим потребностям, может сэкономить много времени на разработку.
Потоки ОС подходят для небольшого количества задач, поскольку потоки связаны с накладными расходами ЦП и памяти. Создание и переключение между потоками довольно затратно, поскольку даже бездействующие потоки потребляют системные ресурсы. Библиотека пула потоков может помочь снизить некоторые из этих затрат, но не все. Однако потоки позволяют повторно использовать существующий синхронный код без существенных изменений кода — никакой конкретной модели программирования не требуется. В некоторых операционных системах вы также можете изменить приоритет потока, что полезно для драйверов и других приложений, чувствительных к задержкам.
Асинхронность значительно снижает нагрузку на ЦП и память, особенно для рабочих нагрузок с большим количеством задач, связанных с вводом-выводом, таких как серверы и базы данных. При прочих равных у вас может быть на порядки больше задач, чем потоков ОС, потому что асинхронная среда выполнения использует небольшое количество (дорогих) потоков для обработки большого количества (дешёвых) задач. Однако асинхронный Rust приводит к большим двоичным объектам из-за конечных автоматов, сгенерированных из асинхронных функций, и поскольку каждый исполняемый файл включает в себя асинхронную среду выполнения.
И наконец, асинхронное программирование не лучше, чем потоки, оно просто отличается. Если вам не нужна асинхронность из соображений производительности, потоки часто могут быть более простой альтернативой.
Пример: одновременная загрузка
В этом примере наша цель — загрузить две веб-страницы одновременно. В типичном многопоточном приложении нам нужно создавать потоки для достижения параллелизма:
fn get_two_sites() {
// Spawn two threads to do work.
let thread_one = thread::spawn(|| download("https://www.foo.com"));
let thread_two = thread::spawn(|| download("https://www.bar.com"));
// Wait for both threads to complete.
thread_one.join().expect("thread one panicked");
thread_two.join().expect("thread two panicked");
}
Однако загрузка веб-страницы — несложная задача; создание потока для такого небольшого объёма работы довольно расточительно. Для более крупного приложения это может легко стать узким местом. В асинхронном Rust мы можем выполнять эти задачи одновременно без дополнительных потоков:
async fn get_two_sites_async() {
// Create two different "futures" which, when run to completion,
// will asynchronously download the webpages.
let future_one = download_async("https://www.foo.com");
let future_two = download_async("https://www.bar.com");
// Run both futures to completion at the same time.
join!(future_one, future_two);
}
Здесь не создаются дополнительные потоки. Кроме того, все вызовы функций обеспечиваются статически, и нет выделения кучи! Однако в первую очередь нам нужно написать код, который будет асинхронным, и эта книга поможет вам в этом.
Пользовательские модели параллелизма в Rust
И наконец, Rust не заставляет вас выбирать между потоками и асинхронностью. Вы можете использовать обе модели в одном и том же приложении, что может быть полезно, когда у вас есть смешанные многопоточные и асинхронные зависимости. На самом деле вы даже можете использовать другую модель параллелизма, например программирование, управляемое событиями (event-driven programming), если найдёте библиотеку, которая её реализует.
Состояние асинхронности в Rust
Части асинхронного Rust поддерживаются с теми же гарантиями стабильности, что и синхронный Rust. Другие части всё ещё созревают и будут меняться со временем. С асинхронным Rust вы можете ожидать:
- Выдающаяся производительность во время выполнения для типичных одновременных рабочих нагрузок.
- Более частое взаимодействие с расширенными функциями языка, такими как время жизни и закрепление (pinning).
- Некоторые ограничения совместимости, как между синхронизирующим и асинхронным кодом, так и между разными асинхронными средами выполнения.
- Более высокая нагрузка на обслуживание из-за продолжающейся эволюции асинхронных сред выполнения и языковой поддержки.
Короче говоря, асинхронный Rust более сложен в использовании и может привести к более высокой нагрузке на обслуживание, чем синхронный Rust, но взамен даёт вам лучшую в своём классе производительность. Все области асинхронного Rust постоянно улучшаются, поэтому влияние этих проблем со временем исчезнет.
Языковая и библиотечная поддержка
Хотя асинхронное программирование поддерживается самим Rust, большинство асинхронных приложений зависят от функциональности, предоставляемой пакетами сообщества. Таким образом, вам нужно полагаться на сочетание языковых функций и поддержки библиотек:
- Наиболее фундаментальные трейты, типы и функции, такие как трейт
Future, предоставляются стандартной библиотекой. - Синтаксис
async/awaitнапрямую поддерживается компилятором Rust. - Пакет Futures предоставляет множество типов
futures, макросов и функций. Их можно использовать в любом асинхронном приложении Rust. - Выполнение асинхронного кода, ввод-вывод и порождение задач обеспечивается «асинхронными средами выполнения», такими как Tokio и async-std. Большинство асинхронных приложений и некоторые асинхронные трейты зависят от конкретной среды выполнения. Дополнительные сведения см. в разделе «Асинхронная экосистема» .
Некоторые языковые функции, к которым вы могли привыкнуть в синхронном Rust, пока недоступны в асинхронном Rust. Примечательно, что Rust не позволяет объявлять асинхронные функции в трейтах. Вместо этого вам нужно использовать обходные пути для достижения того же результата, который может быть более подробным.
Компиляция и отладка
По большей части ошибки компиляции и времени выполнения в асинхронном Rust работают так же, как и всегда в Rust. Есть несколько примечательных отличий:
Ошибки компиляции
Ошибки компиляции в асинхронном Rust соответствуют тем же высоким стандартам, что и в синхронном Rust, но поскольку асинхронный Rust часто зависит от более сложных языковых функций, таких как время жизни и закрепление, вы можете чаще сталкиваться с этими типами ошибок.
Ошибки времени выполнения
Всякий раз, когда компилятор встречает асинхронную функцию, он внутри генерирует конечный автомат. Трассировки стека в асинхронном Rust обычно содержат детали из этих конечных автоматов, а также вызовы функций из среды выполнения. Таким образом, интерпретация трассировки стека может быть немного сложнее, чем в синхронном Rust.
Новые режимы сбоев
В асинхронном Rust возможны несколько новых режимов сбоев, например, если вы вызываете блокирующую функцию из асинхронного контекста или неправильно реализуете трейт Future. Такие ошибки могут незаметно проходить как компилятор, так и иногда даже модульные тесты. Чёткое понимание основных концепций, которое призвана дать вам эта книга, может помочь вам избежать этих ловушек.
Вопросы совместимости
Асинхронный и синхронный код не всегда можно свободно комбинировать. Например, вы не можете напрямую вызвать асинхронную функцию из функции синхронизации. Синхронный и асинхронный код также склонны продвигать разные шаблоны проектирования, что может затруднить создание кода, предназначенного для разных сред.
Даже асинхронный код не всегда можно свободно комбинировать. Работа некоторых крейтов зависит от конкретной асинхронной среды выполнения. Если это так, то это обычно указывается в списке зависимостей крейта.
Эти проблемы с совместимостью могут ограничить ваши возможности, поэтому заранее изучите, какая асинхронная среда выполнения и какие крейты могут понадобиться вам. Как только вы освоитесь со средой выполнения, вам не придётся сильно беспокоиться о совместимости.
Характеристики производительности
Производительность асинхронного Rust зависит от реализации используемой вами асинхронной среды выполнения. Несмотря на то, что среды выполнения, на которых работают асинхронные приложения Rust, относительно новые, они исключительно хорошо работают для большинства практических рабочих нагрузок.
Тем не менее, большая часть асинхронной экосистемы предполагает многопоточную среду выполнения. Это затрудняет использование теоретических преимуществ производительности однопоточных асинхронных приложений, а именно более дешёвой синхронизации. Ещё один упускаемый из виду вариант использования — это задачи, чувствительные к задержкам, которые важны для драйверов, приложений с графическим интерфейсом и т. д. Такие задачи зависят от среды выполнения и/или поддержки ОС, чтобы их можно было планировать соответствующим образом. Вы можете рассчитывать на лучшую библиотечную поддержку для этих вариантов использования в будущем.
Пример async/.await
async/.await - инструменты для написания асинхронного кода встроенные в Rust, внешне похожие на синхронный код. Ключевое слово async превращает исполняемый блок программы в конечный автомат, который реализует типаж Future. В синхронном методе вызов функции блокирует весь поток, в асинхронном же вызов через Future вернёт контроль над потоком, позволяя работать другим Future.
Добавим некоторые зависимости в файл Cargo.toml:
[dependencies]
futures = "0.3"
При реализации асинхронной функции можно использовать такой синтаксис async fn:
#![allow(unused)] fn main() { async fn do_something() { /* ... */ } }
async fn возвращает значение, которые является Future. Что бы ни произошло, Future должна быть запущена в исполнителе.
// `block_on` blocks the current thread until the provided future has run to // completion. Other executors provide more complex behavior, like scheduling // multiple futures onto the same thread. use futures::executor::block_on; async fn hello_world() { println!("hello, world!"); } fn main() { let future = hello_world(); // Nothing is printed block_on(future); // `future` is run and "hello, world!" is printed }
Внутри async fn можно использовать .await для ожидания завершения другой реализации типажа Future, например, полученной из другой async fn). В отличие от block_on, .await не блокирует текущий поток, а асинхронно ожидает завершения футуры, позволяя другим задачам в потоке выполняться, пока эта футура не может быть исполнена.
Например, представим что у нас есть три асинхронные функции async fn: learn_song, sing_song и dance:
async fn learn_song() -> Song { ... }
async fn sing_song(song: Song) { ... }
async fn dance() { ... }
Одним из способов выполнения функций «разучить песню», «спеть» и «станцевать» будет блокировка потока исполнения на каждой из них индивидуально:
fn main() {
let song = block_on(learn_song());
block_on(sing_song(song));
block_on(dance());
}
В этом случае мы не достигаем наилучшей производительности - в один момент времени мы делаем только одно дело! Конечно, мы должны выучить песню до того, как петь её, но мы можем танцевать одновременно с разучиванием песни и пением. Чтобы провернуть такой вариант, создадим две отдельные функции с async fn, которые могут запуститься параллельно:
async fn learn_and_sing() {
// Wait until the song has been learned before singing it.
// We use `.await` here rather than `block_on` to prevent blocking the
// thread, which makes it possible to `dance` at the same time.
let song = learn_song().await;
sing_song(song).await;
}
async fn async_main() {
let f1 = learn_and_sing();
let f2 = dance();
// `join!` is like `.await` but can wait for multiple futures concurrently.
// If we're temporarily blocked in the `learn_and_sing` future, the `dance`
// future will take over the current thread. If `dance` becomes blocked,
// `learn_and_sing` can take back over. If both futures are blocked, then
// `async_main` is blocked and will yield to the executor.
futures::join!(f1, f2);
}
fn main() {
block_on(async_main());
}
В этом примере, разучивание песни должно быть завершено до пения, но разучивание и пение могут завершиться одновременно с танцем. Если бы мы использовали block_on(learn_song()) вместо learn_song().await внутри learn_and_sing, поток не смог бы делать ничего другого, пока работает learn_song. Из-за этого мы одновременно с этим не можем танцевать. С помощью ожидания .await футурыlearn_song, мы разрешаем другим задачам захватить текущий поток исполнения, пока learn_song заблокирована. Это даёт возможность запускать нескольких футур в одном потоке параллельно.
Под капотом: выполнение Future и задач
В этом разделе мы рассмотрим как планируются Future и асинхронные задачи. Если вам только интересно изучить как писать высокоуровневый код, который использует существующие типы Future, и не интересно, как работает Future, то можете сразу перейти к главе async/await. Тем не менее, некоторые темы, которые обсуждаются в этой главе, полезны для понимания работы async/await кода и построения новых асинхронных примитивов. Если сейчас вы решили пропустить этот раздел, вы можете добавить его в закладки, чтобы вернуться к нему в будущем.
Теперь давайте рассмотрим типаж Future.
Типаж Future
Типаж Future находится в центре асинхронного программирования в Rust. Future — это асинхронное вычисление, которое может произвести значение (хотя это значение может быть пустым, например ()). Упрощённая версия этого типажа может выглядеть примерно так:
#![allow(unused)] fn main() { trait SimpleFuture { type Output; fn poll(&mut self, wake: fn()) -> Poll<Self::Output>; } enum Poll<T> { Ready(T), Pending, } }
Футуры могут прогрессировать при помощи функции poll, которая продвигает их к завершению, насколько это возможно. Если футура завершается, она возвращает Poll::Ready(result). Если же она всё ещё не готова завершиться, то - Poll::Pending и обрабатывает функцию wake() таким образом, что она будет вызвана, когда Future будет готова прогрессировать. Когда wake() вызван, исполнитель снова вызывает у Future метод poll, чтобы она смогла продвинуться далее.
Без wake(), исполнитель не имеет возможности узнать, когда какая-либо футура может продвинуться, и ему необходимо постоянно опрашивать каждую футуру. С wake() он точно знает какие футуры готовы прогрессировать.
Например, представим ситуацию, когда мы хотим прочитать из сокета, который может иметь, а может и не иметь данных. Если данные есть, мы можем прочитать их и вернуть Poll::Ready(data), но если данных ещё нет, наша футура блокируется и не может продвинуться дальше. Если данных нет, то мы должны зарегистрировать вызов wake, чтобы он был вызван, когда данные появятся в сокете, и сообщил нашему исполнителю, что футура готова прогрессировать. Простая футура SocketRead может выглядеть следующим образом:
pub struct SocketRead<'a> {
socket: &'a Socket,
}
impl SimpleFuture for SocketRead<'_> {
type Output = Vec<u8>;
fn poll(&mut self, wake: fn()) -> Poll<Self::Output> {
if self.socket.has_data_to_read() {
// The socket has data -- read it into a buffer and return it.
Poll::Ready(self.socket.read_buf())
} else {
// The socket does not yet have data.
//
// Arrange for `wake` to be called once data is available.
// When data becomes available, `wake` will be called, and the
// user of this `Future` will know to call `poll` again and
// receive data.
self.socket.set_readable_callback(wake);
Poll::Pending
}
}
}
Такая модель футур позволяет держать вместе несколько асинхронных операций без лишних промежуточных выделений памяти. Одновременный запуск нескольких футур или соединение их в цепочку может быть реализовано при помощи не выделяющей памяти машины состояний, например так:
/// A SimpleFuture that runs two other futures to completion concurrently.
///
/// Concurrency is achieved via the fact that calls to `poll` each future
/// may be interleaved, allowing each future to advance itself at its own pace.
pub struct Join<FutureA, FutureB> {
// Each field may contain a future that should be run to completion.
// If the future has already completed, the field is set to `None`.
// This prevents us from polling a future after it has completed, which
// would violate the contract of the `Future` trait.
a: Option<FutureA>,
b: Option<FutureB>,
}
impl<FutureA, FutureB> SimpleFuture for Join<FutureA, FutureB>
where
FutureA: SimpleFuture<Output = ()>,
FutureB: SimpleFuture<Output = ()>,
{
type Output = ();
fn poll(&mut self, wake: fn()) -> Poll<Self::Output> {
// Attempt to complete future `a`.
if let Some(a) = &mut self.a {
if let Poll::Ready(()) = a.poll(wake) {
self.a.take();
}
}
// Attempt to complete future `b`.
if let Some(b) = &mut self.b {
if let Poll::Ready(()) = b.poll(wake) {
self.b.take();
}
}
if self.a.is_none() && self.b.is_none() {
// Both futures have completed -- we can return successfully
Poll::Ready(())
} else {
// One or both futures returned `Poll::Pending` and still have
// work to do. They will call `wake()` when progress can be made.
Poll::Pending
}
}
}
Здесь показано, как несколько футур могут быть запущены одновременно без необходимости раздельной аллокации, позволяя асинхронным программам быть более эффективными. Аналогично, несколько последовательных футур могут быть запущены одна за другой, как тут:
/// A SimpleFuture that runs two futures to completion, one after another.
//
// Note: for the purposes of this simple example, `AndThenFut` assumes both
// the first and second futures are available at creation-time. The real
// `AndThen` combinator allows creating the second future based on the output
// of the first future, like `get_breakfast.and_then(|food| eat(food))`.
pub struct AndThenFut<FutureA, FutureB> {
first: Option<FutureA>,
second: FutureB,
}
impl<FutureA, FutureB> SimpleFuture for AndThenFut<FutureA, FutureB>
where
FutureA: SimpleFuture<Output = ()>,
FutureB: SimpleFuture<Output = ()>,
{
type Output = ();
fn poll(&mut self, wake: fn()) -> Poll<Self::Output> {
if let Some(first) = &mut self.first {
match first.poll(wake) {
// We've completed the first future -- remove it and start on
// the second!
Poll::Ready(()) => self.first.take(),
// We couldn't yet complete the first future.
// Notice that we disrupt the flow of the `poll` function with the `return` statement.
Poll::Pending => return Poll::Pending,
};
}
// Now that the first future is done, attempt to complete the second.
self.second.poll(wake)
}
}
Этот пример показывает, как типаж Future может использоваться для выражения асинхронного управления потоком без необходимости множественной аллокации объектов и глубоко вложенных замыканий. Давайте оставим базовое управление потоком в стороне и поговорим о реальном типаже Future и чем он отличается от написанного нами.
trait Future {
type Output;
fn poll(
// Note the change from `&mut self` to `Pin<&mut Self>`:
self: Pin<&mut Self>,
// and the change from `wake: fn()` to `cx: &mut Context<'_>`:
cx: &mut Context<'_>,
) -> Poll<Self::Output>;
}
Первое, что вы могли заметить, что наш тип self больше не &mut Self, а заменён на Pin<&mut Self>. Мы поговорим о закреплении в следующей секции, но пока что знайте, что оно позволяет нам создавать неперемещаемые футуры, которые могут хранить указатели на собственные поля, например struct MyFut { a: i32, ptr_to_a: *const i32 }. Закрепление необходимо для async/await.
Второе, wake: fn() была изменена на &mut Context<'_>. В SimpleFuture мы использовали вызов указателя на функцию (fn()), чтобы сказать исполнителю, что футура должна быть опрошена. Однако, так как fn() имеет нулевой тип, она не может сохранить информацию о том какая футура вызвала wake.
В реальном мире сложное приложение, такое как web-сервер, может иметь тысячи различных подключений, все пробуждения которых должны обрабатываться отдельно. Тип Context решает это, предоставляя доступ к значению типа Waker, который может быть использован для пробуждения конкретной задачи.
Вызовы задачи при помощи Waker
Обычно футуры не могут разрешиться сразу же, как для них вызвали метод poll. Когда это произойдёт, футура должна быть уверена, что её снова опросят, когда она будет готова прогрессировать. Это решается при помощи типа Waker.
Футура опрашивается как часть "задачи" каждый раз, когда происходит её опрос. Задачи - это высокоуровневые футуры, с которыми работает исполнитель.
Waker предоставляет метод wake(), который может быть использован, чтобы сказать исполнителю, что соответствующая задача должна быть пробуждена. Когда вызывается wake(), исполнитель знает, что задача, связанная с Waker, готова к выполнению, и её футура должна быть опрошена снова.
Waker так же реализует clone(), так что вы можете его копировать, где это необходимо, и хранить.
Давайте попробуем реализовать простой таймер с использованием Waker.
Применение: Создание таймера
В качестве примера, мы просто раскручиваем новый поток при создании таймера, спим в течение необходимого времени, а затем через какое-то время сообщаем о том, что заданный временной промежуток истёк.
Во-первых, запустите новый проект с cargo new --lib timer_future и добавьте импорт, который нам понадобится для начала работы, в src/lib.rs:
#![allow(unused)] fn main() { use std::{ future::Future, pin::Pin, sync::{Arc, Mutex}, task::{Context, Poll, Waker}, thread, time::Duration, }; }
Начнём с определения типа футуры. Нашей футуре необходим канал связи, чтобы сообщить о том, что время таймера истекло и футура должна завершиться. В качестве канала связи между таймером и футурой мы будем использовать разделяемое значение Arc<Mutex<..>>.
pub struct TimerFuture {
shared_state: Arc<Mutex<SharedState>>,
}
/// Shared state between the future and the waiting thread
struct SharedState {
/// Whether or not the sleep time has elapsed
completed: bool,
/// The waker for the task that `TimerFuture` is running on.
/// The thread can use this after setting `completed = true` to tell
/// `TimerFuture`'s task to wake up, see that `completed = true`, and
/// move forward.
waker: Option<Waker>,
}
Теперь давайте реализуем Future для нашей футуры!
impl Future for TimerFuture {
type Output = ();
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output> {
// Look at the shared state to see if the timer has already completed.
let mut shared_state = self.shared_state.lock().unwrap();
if shared_state.completed {
Poll::Ready(())
} else {
// Set waker so that the thread can wake up the current task
// when the timer has completed, ensuring that the future is polled
// again and sees that `completed = true`.
//
// It's tempting to do this once rather than repeatedly cloning
// the waker each time. However, the `TimerFuture` can move between
// tasks on the executor, which could cause a stale waker pointing
// to the wrong task, preventing `TimerFuture` from waking up
// correctly.
//
// N.B. it's possible to check for this using the `Waker::will_wake`
// function, but we omit that here to keep things simple.
shared_state.waker = Some(cx.waker().clone());
Poll::Pending
}
}
}
Просто, не так ли? Если поток установит shared_state.completed = true, мы закончили! В противном случае мы клонируем Waker для текущей задачи и сохраняем его в shared_state.waker. Так поток может разбудить задачу позже.
Важно отметить, что мы должны обновлять Waker каждый раз, когда футура опрашивается, потому что она может быть перемещена в другую задачу с другим Waker. Это может произойти когда футуры после опроса передаются между задачами.
Наконец, нам нужен API, чтобы фактически построить таймер и запустить поток:
impl TimerFuture {
/// Create a new `TimerFuture` which will complete after the provided
/// timeout.
pub fn new(duration: Duration) -> Self {
let shared_state = Arc::new(Mutex::new(SharedState {
completed: false,
waker: None,
}));
// Spawn the new thread
let thread_shared_state = shared_state.clone();
thread::spawn(move || {
thread::sleep(duration);
let mut shared_state = thread_shared_state.lock().unwrap();
// Signal that the timer has completed and wake up the last
// task on which the future was polled, if one exists.
shared_state.completed = true;
if let Some(waker) = shared_state.waker.take() {
waker.wake()
}
});
TimerFuture { shared_state }
}
}
Это всё, что нам нужно, чтобы построить простую футуру таймером. Теперь нам нужен исполнитель, чтобы запустить её на исполнение.
Применение: создание исполнителя
Футуры Rust'a ленивы: они ничего не будут делать, если не будут активно доводиться до завершения. Один из способов довести их до завершения - это .await внутри async функции, но это просто подталкивает проблему на один уровень вверх: кто будет запускать футуры, возвращённые из async функций верхнего уровня? Ответ в том, что нам нужен исполнитель для Future.
Исполнители берут набор футур верхнего уровня и запускают их через вызов метода poll, до тех пока они не завершатся. Как правило, исполнитель будет вызывать метод poll у футуры один раз, чтобы запустить. Когда футуры сообщают, что готовы продолжить вычисления при вызове метода wake(), они помещаются обратно в очередь и вызов poll повторяется до тех пор, пока Future не будут завершены.
В этом разделе мы напишем нашего собственного простого исполнителя, способного одновременно запускать большое количество футур верхнего уровня.
В этом примере мы зависим от futures ящика для трейта ArcWake, который обеспечивает простой способ создания Waker. Отредактируйте Cargo.toml, чтобы добавить новую зависимость:
[package]
name = "timer_future"
version = "0.1.0"
authors = ["XYZ Author"]
edition = "2021"
[dependencies]
futures = "0.3"
Дальше, мы должны в верхней части src/main.rs импортировать следующее:
use futures::{
future::{BoxFuture, FutureExt},
task::{waker_ref, ArcWake},
};
use std::{
future::Future,
sync::mpsc::{sync_channel, Receiver, SyncSender},
sync::{Arc, Mutex},
task::Context,
time::Duration,
};
// The timer we wrote in the previous section:
use timer_future::TimerFuture;
Наш исполнитель будет работать, посылая задачи для запуска по каналу. Исполнитель извлечёт события из канала и запустит их. Когда задача будет готова выполнить больше работы (будет пробуждена), она может запланировать повторный опрос самой себя, отправив себя обратно в канал.
В этом проекте самому исполнителю просто необходим получатель для канала задачи. Пользователь получит экземпляр отправителя, чтобы он мог создавать новые футуры. Сами задачи - это просто футуры, которые могут перезапланировать самих себя, поэтому мы сохраним их как сочетание футуры и отправителя, который задача может использовать, чтобы добавить себя в очередь.
/// Task executor that receives tasks off of a channel and runs them.
struct Executor {
ready_queue: Receiver<Arc<Task>>,
}
/// `Spawner` spawns new futures onto the task channel.
#[derive(Clone)]
struct Spawner {
task_sender: SyncSender<Arc<Task>>,
}
/// A future that can reschedule itself to be polled by an `Executor`.
struct Task {
/// In-progress future that should be pushed to completion.
///
/// The `Mutex` is not necessary for correctness, since we only have
/// one thread executing tasks at once. However, Rust isn't smart
/// enough to know that `future` is only mutated from one thread,
/// so we need to use the `Mutex` to prove thread-safety. A production
/// executor would not need this, and could use `UnsafeCell` instead.
future: Mutex<Option<BoxFuture<'static, ()>>>,
/// Handle to place the task itself back onto the task queue.
task_sender: SyncSender<Arc<Task>>,
}
fn new_executor_and_spawner() -> (Executor, Spawner) {
// Maximum number of tasks to allow queueing in the channel at once.
// This is just to make `sync_channel` happy, and wouldn't be present in
// a real executor.
const MAX_QUEUED_TASKS: usize = 10_000;
let (task_sender, ready_queue) = sync_channel(MAX_QUEUED_TASKS);
(Executor { ready_queue }, Spawner { task_sender })
}
Давайте ещё добавим метод в spawner, чтобы было проще создавать новые футуры. Этот метод возьмёт тип футуры, поместит его в коробку и создаст новую задачу Arc<Task> с ним внутри. И эта задача может быть помещена в очередь для исполнителя.
impl Spawner {
fn spawn(&self, future: impl Future<Output = ()> + 'static + Send) {
let future = future.boxed();
let task = Arc::new(Task {
future: Mutex::new(Some(future)),
task_sender: self.task_sender.clone(),
});
self.task_sender.try_send(task).expect("too many tasks queued");
}
}
Чтобы опросить futures, нам нужно создать Waker. Как описано в разделе задачи пробуждения, Wakers отвечают за планирование задач, которые будут опрошены снова после вызова wake. Wakers сообщают исполнителю, какая именно задача завершилась, позволяя опрашивать как раз те futures, которые готовы к продолжению выполнения. Простой способ создать новый Waker, необходимо реализовать типаж ArcWake, а затем использовать waker_ref или .into_waker() функции для преобразования Arc<impl ArcWake> в Waker. Давайте реализуем ArcWake для наших задач, чтобы они были превращены в Wakers и могли пробуждаться:
impl ArcWake for Task {
fn wake_by_ref(arc_self: &Arc<Self>) {
// Implement `wake` by sending this task back onto the task channel
// so that it will be polled again by the executor.
let cloned = arc_self.clone();
arc_self
.task_sender
.try_send(cloned)
.expect("too many tasks queued");
}
}
Когда Waker создаётся на основе Arc<Task>, вызывая wake(), это вызовет отправку копии Arc в канал задач. Тогда нашему исполнителю нужно подобрать задание и опросить его. Давайте реализуем это:
impl Executor {
fn run(&self) {
while let Ok(task) = self.ready_queue.recv() {
// Take the future, and if it has not yet completed (is still Some),
// poll it in an attempt to complete it.
let mut future_slot = task.future.lock().unwrap();
if let Some(mut future) = future_slot.take() {
// Create a `LocalWaker` from the task itself
let waker = waker_ref(&task);
let context = &mut Context::from_waker(&waker);
// `BoxFuture<T>` is a type alias for
// `Pin<Box<dyn Future<Output = T> + Send + 'static>>`.
// We can get a `Pin<&mut dyn Future + Send + 'static>`
// from it by calling the `Pin::as_mut` method.
if future.as_mut().poll(context).is_pending() {
// We're not done processing the future, so put it
// back in its task to be run again in the future.
*future_slot = Some(future);
}
}
}
}
}
Поздравляю! Теперь у нас есть работающий исполнитель futures. Мы даже можем использовать его для запуска async/.await кода и пользовательских futures, таких как TimerFuture которую мы описали ранее:
fn main() {
let (executor, spawner) = new_executor_and_spawner();
// Spawn a task to print before and after waiting on a timer.
spawner.spawn(async {
println!("howdy!");
// Wait for our timer future to complete after two seconds.
TimerFuture::new(Duration::new(2, 0)).await;
println!("done!");
});
// Drop the spawner so that our executor knows it is finished and won't
// receive more incoming tasks to run.
drop(spawner);
// Run the executor until the task queue is empty.
// This will print "howdy!", pause, and then print "done!".
executor.run();
}
Исполнители и системный ввод/вывод
В главе "Типаж Future", мы обсуждали футуру, которая выполняет асинхронное чтение сокета:
#![allow(unused)] fn main() { pub struct SocketRead<'a> { socket: &'a Socket, } impl SimpleFuture for SocketRead<'_> { type Output = Vec<u8>; fn poll(&mut self, wake: fn()) -> Poll<Self::Output> { if self.socket.has_data_to_read() { // The socket has data -- read it into a buffer and return it. Poll::Ready(self.socket.read_buf()) } else { // The socket does not yet have data. // // Arrange for `wake` to be called once data is available. // When data becomes available, `wake` will be called, and the // user of this `Future` will know to call `poll` again and // receive data. self.socket.set_readable_callback(wake); Poll::Pending } } } }
Эта футура читает из сокета доступные данные и если таковых нет, то она передаётся исполнителю с запросом
активирования задачи, когда сокет снова станет читаемым. Однако,
из текущего примера не ясна реализация типа
Socket и, в частности, не совсем очевидно как
работает функция set_readable_callback. Как мы
можем сделать так, чтобы lw.wake() был вызван,
когда сокет станет читаемым? Один из вариантов - иметь поток,
который постоянно проверяет стал ли socket
читаемым, вызывая при необходимости метод
wake(). Тем не менее, такой подход будет весьма не
эффективным, так как он требует отдельного потока для каждой
блокирующей IO футуры. Это значительно снизит эффективность
нашего асинхронного кода.
На практике эта проблема решается при помощи интеграции с
IO-зависимыми системными блокирующими примитивами такими,
как epoll в Linux, kqueue во FreeBSD и
Mac OS, IOCP в Windows и port в Fuchsia (все они
предоставляются при помощи кроссплатформенного Rust-пакета
mio). Все эти примитивы позволяют потоку
заблокироваться с несколькими асинхронными IO-событиями,
возвращая одно из завершённых событий. На практике эти API
выглядят примерно так:
#![allow(unused)] fn main() { struct IoBlocker { ... } struct Event { // ID уникально идентифицирующий событие, которое уже произошло и на которое мы подписались id: usize, // Набор сигналов, которые мы ожидаем или которые произошли signals: Signals, } impl IoBlocker { /// Создаём новую коллекцию асинхронных IO-событий для блокировки fn new() -> Self { ... } /// Подпишемся на определённое IO-событие. fn add_io_event_interest( &self, /// Объект, на котором происходит событие io_object: &IoObject, /// Набор сигналов, которые могут применяться к `io_object`, /// для которого должно быть инициировано событие, в паре с /// ID, которые передадутся событиям, получившимся в результате нашей подписки. event: Event, ) { ... } /// Заблокируется до появления одного из событий fn block(&self) -> Event { ... } } let mut io_blocker = IoBlocker::new(); io_blocker.add_io_event_interest( &socket_1, Event { id: 1, signals: READABLE }, ); io_blocker.add_io_event_interest( &socket_2, Event { id: 2, signals: READABLE | WRITABLE }, ); let event = io_blocker.block(); // выведет что-то похожее на "Socket 1 is now READABLE", если сокет станет доступным для чтения. println!("Socket {:?} is now {:?}", event.id, event.signals); }
Исполнители футур могут использовать эти примитивы для предоставления асинхронных объектов ввода-вывода,
таких как сокеты, которые могут настроить обратные вызовы для запуска при определённом IO-событии. В случае нашего примера c SocketRead, функция Socket::set_readable_callback может выглядеть следующим псевдокодом:
#![allow(unused)] fn main() { impl Socket { fn set_readable_callback(&self, waker: Waker) { // `local_executor` является ссылкой на локальный исполнитель. // Это может быть предусмотрено при создании сокета, // большинство реализаций исполнителей делают это через локальный поток, так удобнее. let local_executor = self.local_executor; // Уникальный ID для объекта ввода вывода. let id = self.id; // Сохраним `waker` в данных исполнителя, // чтобы его можно было вызвать после того, как будет получено событие. local_executor.event_map.insert(id, waker); local_executor.add_io_event_interest( &self.socket_file_descriptor, Event { id, signals: READABLE }, ); } } }
Теперь у нас может быть только один поток исполнителя, который может принимать и отправлять любые
события ввода-вывода в нужный Waker, который разбудит соответствующую
задачу, позволяющая исполнителю довести больше задач до завершения перед возвратом к проверке новых событий ввода-вывода (и цикл продолжается...).
async/.await
В первой главе мы бросили беглый взгляд на async/.await. В этой главе мы обсудим async/.await более подробно, объясняя, как они работают и чем async-код отличается от традиционных программ на Rust.
async/.await - это специальный синтаксис Rust, который позволяет не блокировать поток, а передавать управление другому коду, пока ожидается завершение операции.
Существует два основных способа использования async: async fn и async-блоки. Каждый возвращает значение, реализующее типаж Future:
// `foo()` returns a type that implements `Future<Output = u8>`.
// `foo().await` will result in a value of type `u8`.
async fn foo() -> u8 { 5 }
fn bar() -> impl Future<Output = u8> {
// This `async` block results in a type that implements
// `Future<Output = u8>`.
async {
let x: u8 = foo().await;
x + 5
}
}
Как мы видели в первой главе, async-блоки и другие футуры ленивы: они ничего не делают, пока их не запустят. Наиболее распространённый способ запустить Future - это .await. Когда .await вызывается на Future, он пытается выполнить её до конца. Если Future заблокирована, то контроль будет передан текущему потоку. Чтобы добиться большего прогресса, будет выбрана верхняя Future исполнителя, позволяя .await продолжить работу.
Времена жизни async
В отличие от традиционных функций, async fn, которые принимают ссылки или другие не-'static аргументы, возвращают Future, которая ограничена временем жизни аргумента:
// This function:
async fn foo(x: &u8) -> u8 { *x }
// Is equivalent to this function:
fn foo_expanded<'a>(x: &'a u8) -> impl Future<Output = u8> + 'a {
async move { *x }
}
Это означает, что для футуры, возвращаемая из async fn, должен быть вызван .await до тех пор, пока её не-'static аргументы все ещё действительны. В общем случае, вызов .await у футуры сразу после вызова функции (как в foo(&x).await), не является проблемой. Однако, проблемой может оказаться сохранение футуры или отправка её в другую задачу или поток.
Один общий обходной путь для включения async fn со ссылками в аргументах в 'static футуру состоит в том, чтобы связать аргументы с вызовом async fn внутри async-блока:
fn bad() -> impl Future<Output = u8> {
let x = 5;
borrow_x(&x) // ERROR: `x` does not live long enough
}
fn good() -> impl Future<Output = u8> {
async {
let x = 5;
borrow_x(&x).await
}
}
Перемещая аргумент в async-блок, мы продлеваем его время жизни до времени жизни Future, которая возвращается при вызове good.
async move
async-блоки и async-замыкания позволяют использовать ключевое слово move, как и в обычном замыкании. async move блок получает владение переменными со ссылками, позволяя им пережить текущую область, но отказывая им в возможности делиться этими переменными с другим кодом:
/// `async` block:
///
/// Multiple different `async` blocks can access the same local variable
/// so long as they're executed within the variable's scope
async fn blocks() {
let my_string = "foo".to_string();
let future_one = async {
// ...
println!("{my_string}");
};
let future_two = async {
// ...
println!("{my_string}");
};
// Run both futures to completion, printing "foo" twice:
let ((), ()) = futures::join!(future_one, future_two);
}
/// `async move` block:
///
/// Only one `async move` block can access the same captured variable, since
/// captures are moved into the `Future` generated by the `async move` block.
/// However, this allows the `Future` to outlive the original scope of the
/// variable:
fn move_block() -> impl Future<Output = ()> {
let my_string = "foo".to_string();
async move {
// ...
println!("{my_string}");
}
}
.await в многопоточном исполнителе
Обратите внимание, что при использовании Future в многопоточном исполнителе, Future может перемещаться между потоками. Поэтому любые переменные, используемые в телах async, должны иметь возможность перемещаться между потоками, так как любой .await потенциально может привести к переключению на новый поток.
Это означает, что не безопасно использовать Rc, &RefCell или любые другие типы, не реализующие типаж Send (включая ссылки на типы, которые не реализуют типаж Sync).
(Предостережение: эти типы можно использовать, если они не находятся в области видимости во время вызова .await.)
Точно так же не очень хорошая идея держать традиционную non-futures-aware блокировку через .await, так как это может привести к блокировке пула потоков: одна задача может получить объект блокировки, вызвать .await и передать управление исполнителю, разрешив другой задаче совершить попытку взять блокировку, что вызовет взаимную блокировку. Чтобы избежать этого, используйте Mutex из futures::lock, а не из std::sync.
Закрепление
Чтобы можно было опросить футуры, они должны быть закреплены с помощью специального типа Pin<T>. Если вы прочитали объяснение типажа Future в предыдущем разделе «Выполнение Future и задач», вы узнаете Pin из self: Pin<&mut Self> в определении метода Future::poll. Но что это значит, и зачем нам это нужно?
Для чего нужно закрепление
Pin работает в тандеме с маркером Unpin. Закрепление позволяет гарантировать, что объект, реализующий !Unpin, никогда не будет перемещён. Чтобы понять, зачем это нужно, нужно вспомнить, как работает async/.await. Рассмотрим следующий код:
let fut_one = /* ... */;
let fut_two = /* ... */;
async move {
fut_one.await;
fut_two.await;
}
Под капотом создаётся анонимный тип, который реализует типаж Future и метод poll:
// Тип `Future`, созданный нашим `async { ... }`-блоком
struct AsyncFuture {
fut_one: FutOne,
fut_two: FutTwo,
state: State,
}
// Список состояний нашего `async`-блока
enum State {
AwaitingFutOne,
AwaitingFutTwo,
Done,
}
impl Future for AsyncFuture {
type Output = ();
fn poll(mut self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<()> {
loop {
match self.state {
State::AwaitingFutOne => match self.fut_one.poll(..) {
Poll::Ready(()) => self.state = State::AwaitingFutTwo,
Poll::Pending => return Poll::Pending,
}
State::AwaitingFutTwo => match self.fut_two.poll(..) {
Poll::Ready(()) => self.state = State::Done,
Poll::Pending => return Poll::Pending,
}
State::Done => return Poll::Ready(()),
}
}
}
}
Когда poll вызывается первый раз, он опрашивает fut_one. Если fut_one не завершена, возвращается AsyncFuture::poll. Следующие вызовы poll будут начинаться там, где завершился предыдущий вызов. Этот процесс продолжается до тех пор, пока футура не будет завершена.
Однако что будет, если async-блок использует ссылки? Например:
async {
let mut x = [0; 128];
let read_into_buf_fut = read_into_buf(&mut x);
read_into_buf_fut.await;
println!("{:?}", x);
}
Во что скомпилируется эта структура?
struct ReadIntoBuf<'a> {
buf: &'a mut [u8], // указывает на `x` ниже
}
struct AsyncFuture {
x: [u8; 128],
read_into_buf_fut: ReadIntoBuf<'?>, // какое тут время жизни?
}
Здесь футура ReadIntoBuf содержит ссылку на другое поле нашей структуры, x. Однако, если AsyncFuture будет перемещена, положение x тоже будет изменено, что инвалидирует указатель, сохранённый в read_into_buf_fut.buf.
Закрепление футур в определённом месте памяти предотвращает эту проблему, делая безопасным создание ссылок на данные за пределами async-блока.
Как устроено закрепление
Давайте попробуем понять закрепление на более простом примере. Проблема, с которой мы столкнулись выше, — это проблема, которая в конечном итоге сводится к тому, как мы обрабатываем ссылки в самоссылающихся типах в Rust.
Пусть наш пример будет выглядеть так:
#![allow(unused)] fn main() { #[derive(Debug)] struct Test { a: String, b: *const String, } impl Test { fn new(txt: &str) -> Self { Test { a: String::from(txt), b: std::ptr::null(), } } fn init(&mut self) { let self_ref: *const String = &self.a; self.b = self_ref; } fn a(&self) -> &str { &self.a } fn b(&self) -> &String { assert!(!self.b.is_null(), "Test::b called without Test::init being called first"); unsafe { &*(self.b) } } } }
Test предоставляет методы для получения ссылки на значение полей a и b. Поскольку b является ссылкой на a, мы храним его как указатель, так как правила заимствования Rust не позволяют нам определять его время жизни. Теперь у нас есть то, что мы называем самоссылающейся структурой.
Наш пример работает нормально, если мы не перемещаем какие-либо наши данные, как вы можете наблюдать в этом примере:
fn main() { let mut test1 = Test::new("test1"); test1.init(); let mut test2 = Test::new("test2"); test2.init(); println!("a: {}, b: {}", test1.a(), test1.b()); println!("a: {}, b: {}", test2.a(), test2.b()); } #[derive(Debug)] struct Test { a: String, b: *const String, } impl Test { fn new(txt: &str) -> Self { Test { a: String::from(txt), b: std::ptr::null(), } } // Мы должны реализовать метод `init`, чтобы сделать ссылку на себя fn init(&mut self) { let self_ref: *const String = &self.a; self.b = self_ref; } fn a(&self) -> &str { &self.a } fn b(&self) -> &String { assert!(!self.b.is_null(), "Test::b called without Test::init being called first"); unsafe { &*(self.b) } } }
Мы получили, что ожидали:
#![allow(unused)] fn main() { a: test1, b: test1 a: test2, b: test2 }
Давайте посмотрим, что произойдёт, если мы поменяем местами test1 с test2, тем самым переместив данные:
fn main() { let mut test1 = Test::new("test1"); test1.init(); let mut test2 = Test::new("test2"); test2.init(); println!("a: {}, b: {}", test1.a(), test1.b()); std::mem::swap(&mut test1, &mut test2); println!("a: {}, b: {}", test2.a(), test2.b()); } #[derive(Debug)] struct Test { a: String, b: *const String, } impl Test { fn new(txt: &str) -> Self { Test { a: String::from(txt), b: std::ptr::null(), } } fn init(&mut self) { let self_ref: *const String = &self.a; self.b = self_ref; } fn a(&self) -> &str { &self.a } fn b(&self) -> &String { assert!(!self.b.is_null(), "Test::b called without Test::init being called first"); unsafe { &*(self.b) } } }
Очевидно, этот код должен напечатать test1 дважды:
#![allow(unused)] fn main() { a: test1, b: test1 a: test1, b: test1 }
Но вместо этого получаем:
#![allow(unused)] fn main() { a: test1, b: test1 a: test1, b: test2 }
Указатель на test2.b по-прежнему указывает на старое местоположение, которое сейчас находится внутри test1. Структура больше не является самоссылающейся, она содержит указатель на поле в другом объекте. Это означает, что мы больше не можем полагаться на то, что время жизни test2.b будет привязано к времени жизни test2 .
Если вы всё ещё не убеждены, это должно убедить вас:
fn main() { let mut test1 = Test::new("test1"); test1.init(); let mut test2 = Test::new("test2"); test2.init(); println!("a: {}, b: {}", test1.a(), test1.b()); std::mem::swap(&mut test1, &mut test2); test1.a = "I've totally changed now!".to_string(); println!("a: {}, b: {}", test2.a(), test2.b()); } #[derive(Debug)] struct Test { a: String, b: *const String, } impl Test { fn new(txt: &str) -> Self { Test { a: String::from(txt), b: std::ptr::null(), } } fn init(&mut self) { let self_ref: *const String = &self.a; self.b = self_ref; } fn a(&self) -> &str { &self.a } fn b(&self) -> &String { assert!(!self.b.is_null(), "Test::b called without Test::init being called first"); unsafe { &*(self.b) } } }
Диаграмма ниже может помочь визуализировать происходящее:
Из. 1: До и после замены 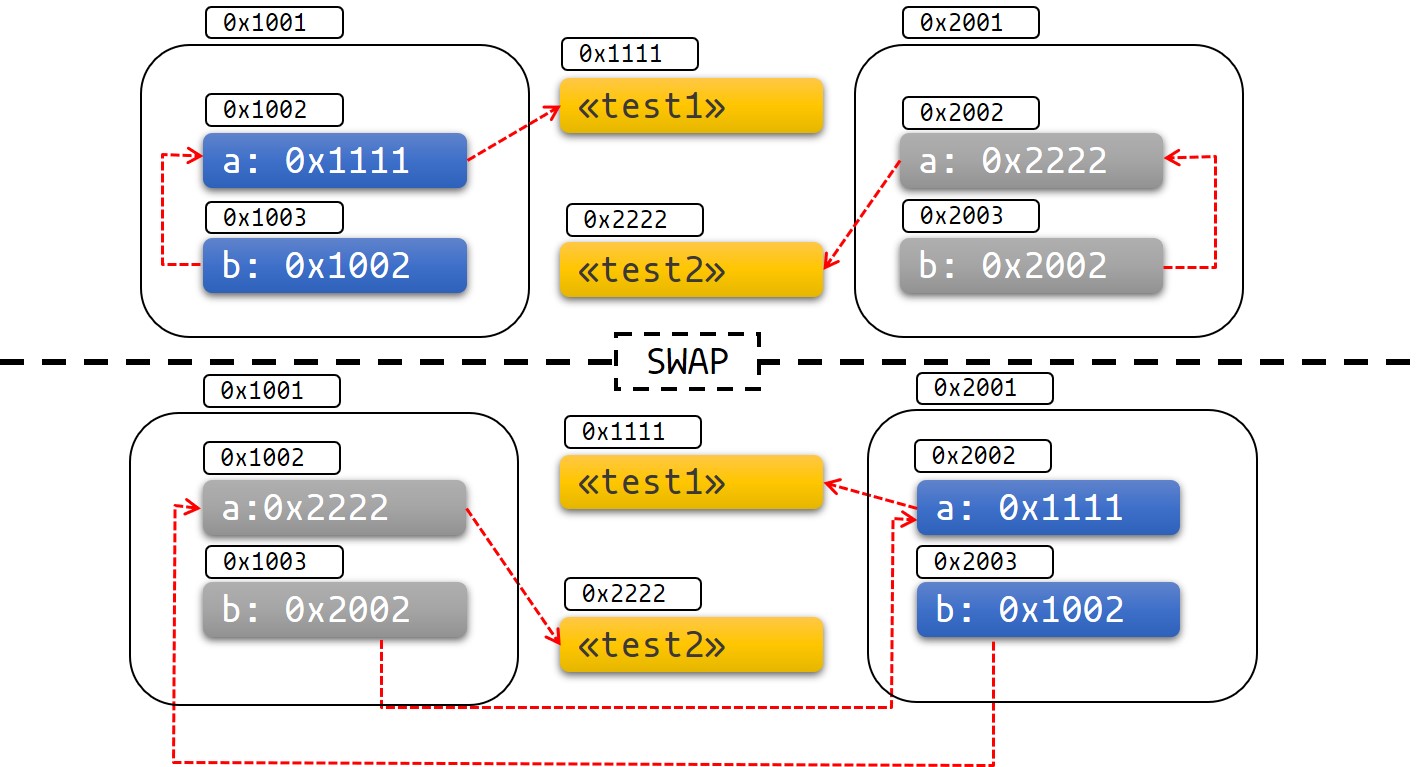
Здесь легко получить неопределённое поведение и другие ошеломляющие ошибки.
Как использовать закрепление
Давайте посмотрим, как закрепление и тип Pin могут помочь нам решить эту проблему.
Тип Pin оборачивает типы указателей, гарантируя, что значения за указателем не будут перемещены, если они не реализуют Unpin. Например, Pin<&mut T>, Pin<&T>, Pin<Box<T>> гарантируют, что T не будет перемещён, если T: !Unpin .
У большинства типов нет проблем с перемещением, так как они реализуют типаж Unpin. Указатели на типы Unpin можно свободно помещать в Pin или извлекать из него. Например, u8 реализует Unpin, поэтому Pin<&mut u8> ведёт себя так же, как обычный &mut u8.
Однако типы, которые нельзя переместить после закрепления, имеют маркер !Unpin. Футуры, созданные с помощью async/await, являются примером этого.
Закрепление на стеке
Вернёмся к нашему примеру. Мы можем решить нашу проблему, используя Pin. Давайте посмотрим, как выглядел бы наш пример, если бы вместо этого нам требовался закреплённый указатель:
#![allow(unused)] fn main() { use std::pin::Pin; use std::marker::PhantomPinned; #[derive(Debug)] struct Test { a: String, b: *const String, _marker: PhantomPinned, } impl Test { fn new(txt: &str) -> Self { Test { a: String::from(txt), b: std::ptr::null(), _marker: PhantomPinned, // Делаем наш тип `!Unpin` } } fn init(self: Pin<&mut Self>) { let self_ptr: *const String = &self.a; let this = unsafe { self.get_unchecked_mut() }; this.b = self_ptr; } fn a(self: Pin<&Self>) -> &str { &self.get_ref().a } fn b(self: Pin<&Self>) -> &String { assert!(!self.b.is_null(), "Test::b called without Test::init being called first"); unsafe { &*(self.b) } } } }
Закрепление объекта на стеке всегда будет unsafe, если наш тип реализует !Unpin. Вы можете использовать такой крейт, как pin_utils, чтобы избежать написания собственного unsafe кода при закреплении на стеке.
Ниже мы закрепляем объекты test1 и test2 на стеке:
pub fn main() { // test1 безопасен для перемещения, пока мы не инициализировали его let mut test1 = Test::new("test1"); // Обратите внимание, как мы затенили `test1` для предотвращения повторного доступа к нему let mut test1 = unsafe { Pin::new_unchecked(&mut test1) }; Test::init(test1.as_mut()); let mut test2 = Test::new("test2"); let mut test2 = unsafe { Pin::new_unchecked(&mut test2) }; Test::init(test2.as_mut()); println!("a: {}, b: {}", Test::a(test1.as_ref()), Test::b(test1.as_ref())); println!("a: {}, b: {}", Test::a(test2.as_ref()), Test::b(test2.as_ref())); } use std::pin::Pin; use std::marker::PhantomPinned; #[derive(Debug)] struct Test { a: String, b: *const String, _marker: PhantomPinned, } impl Test { fn new(txt: &str) -> Self { Test { a: String::from(txt), b: std::ptr::null(), // Делаем наш тип `!Unpin` _marker: PhantomPinned, } } fn init(self: Pin<&mut Self>) { let self_ptr: *const String = &self.a; let this = unsafe { self.get_unchecked_mut() }; this.b = self_ptr; } fn a(self: Pin<&Self>) -> &str { &self.get_ref().a } fn b(self: Pin<&Self>) -> &String { assert!(!self.b.is_null(), "Test::b called without Test::init being called first"); unsafe { &*(self.b) } } }
Теперь, если мы попытаемся переместить наши данные, мы получим ошибку компиляции:
pub fn main() { let mut test1 = Test::new("test1"); let mut test1 = unsafe { Pin::new_unchecked(&mut test1) }; Test::init(test1.as_mut()); let mut test2 = Test::new("test2"); let mut test2 = unsafe { Pin::new_unchecked(&mut test2) }; Test::init(test2.as_mut()); println!("a: {}, b: {}", Test::a(test1.as_ref()), Test::b(test1.as_ref())); std::mem::swap(test1.get_mut(), test2.get_mut()); println!("a: {}, b: {}", Test::a(test2.as_ref()), Test::b(test2.as_ref())); } use std::pin::Pin; use std::marker::PhantomPinned; #[derive(Debug)] struct Test { a: String, b: *const String, _marker: PhantomPinned, } impl Test { fn new(txt: &str) -> Self { Test { a: String::from(txt), b: std::ptr::null(), _marker: PhantomPinned, // Делаем наш тип `!Unpin` } } fn init(self: Pin<&mut Self>) { let self_ptr: *const String = &self.a; let this = unsafe { self.get_unchecked_mut() }; this.b = self_ptr; } fn a(self: Pin<&Self>) -> &str { &self.get_ref().a } fn b(self: Pin<&Self>) -> &String { assert!(!self.b.is_null(), "Test::b called without Test::init being called first"); unsafe { &*(self.b) } } }
Система типов не позволяет нам перемещать данные, как показано здесь:
error[E0277]: `PhantomPinned` cannot be unpinned
--> src\test.rs:56:30
|
56 | std::mem::swap(test1.get_mut(), test2.get_mut());
| ^^^^^^^ within `test1::Test`, the trait `Unpin` is not implemented for `PhantomPinned`
|
= note: consider using `Box::pin`
note: required because it appears within the type `test1::Test`
--> src\test.rs:7:8
|
7 | struct Test {
| ^^^^
note: required by a bound in `std::pin::Pin::<&'a mut T>::get_mut`
--> <...>rustlib/src/rust\library\core\src\pin.rs:748:12
|
748 | T: Unpin,
| ^^^^^ required by this bound in `std::pin::Pin::<&'a mut T>::get_mut`
Важно отметить, что закрепление на стеке всегда будет зависеть от гарантий, которые вы даёте при написании
unsafe. Хотя мы знаем, что указатель типа&'a mut Tзакреплён на время жизни'a, мы не можем знать, перемещаются ли данные, на которые указывает&'a mut T, после окончания'a. Если это произойдёт, это нарушит контракт Pin.Ошибка, которую легко сделать, это забыть затенить исходную переменную, так как вы можете удалить
Pinи переместить данные после&'a mut T, как показано ниже (что нарушает контракт Pin):fn main() { let mut test1 = Test::new("test1"); let mut test1_pin = unsafe { Pin::new_unchecked(&mut test1) }; Test::init(test1_pin.as_mut()); drop(test1_pin); println!(r#"test1.b points to "test1": {:?}..."#, test1.b); let mut test2 = Test::new("test2"); mem::swap(&mut test1, &mut test2); println!("... and now it points nowhere: {:?}", test1.b); } use std::pin::Pin; use std::marker::PhantomPinned; use std::mem; #[derive(Debug)] struct Test { a: String, b: *const String, _marker: PhantomPinned, } impl Test { fn new(txt: &str) -> Self { Test { a: String::from(txt), b: std::ptr::null(), // Делаем наш тип `!Unpin` _marker: PhantomPinned, } } fn init<'a>(self: Pin<&'a mut Self>) { let self_ptr: *const String = &self.a; let this = unsafe { self.get_unchecked_mut() }; this.b = self_ptr; } fn a<'a>(self: Pin<&'a Self>) -> &'a str { &self.get_ref().a } fn b<'a>(self: Pin<&'a Self>) -> &'a String { assert!(!self.b.is_null(), "Test::b called without Test::init being called first"); unsafe { &*(self.b) } } }
Закрепление на куче
Закрепление типа !Unpin на куче даёт нашим данным постоянный адрес, поэтому мы знаем, что данные, на которые мы указываем, не могут перемещаться после закрепления. В отличие от закрепления на стеке, мы знаем, что данные будут закреплены на время жизни объекта.
use std::pin::Pin; use std::marker::PhantomPinned; #[derive(Debug)] struct Test { a: String, b: *const String, _marker: PhantomPinned, } impl Test { fn new(txt: &str) -> Pin<Box<Self>> { let t = Test { a: String::from(txt), b: std::ptr::null(), _marker: PhantomPinned, }; let mut boxed = Box::pin(t); let self_ptr: *const String = &boxed.a; unsafe { boxed.as_mut().get_unchecked_mut().b = self_ptr }; boxed } fn a(self: Pin<&Self>) -> &str { &self.get_ref().a } fn b(self: Pin<&Self>) -> &String { unsafe { &*(self.b) } } } pub fn main() { let test1 = Test::new("test1"); let test2 = Test::new("test2"); println!("a: {}, b: {}",test1.as_ref().a(), test1.as_ref().b()); println!("a: {}, b: {}",test2.as_ref().a(), test2.as_ref().b()); }
Некоторые функции требуют, чтобы футуры, с которыми они работают, были Unpin. Чтобы использовать Future или Stream, которые не являются Unpin, с функцией, требующей Unpin-тип, вам сначала нужно закрепить значение с помощью Box::pin, создав Pin<Box<T>>, или макроса pin_utils::pin_mut!, создав Pin<&mut T>. Pin<Box<Fut>> и Pin<&mut Fut> могут использоваться как футуры, и оба реализуют Unpin.
Например:
use pin_utils::pin_mut; // `pin_utils` -- это удобный крейт из crates.io
// Функций принимает `Future`, реализующую `Unpin`.
fn execute_unpin_future(x: impl Future<Output = ()> + Unpin) { /* ... */ }
let fut = async { /* ... */ };
execute_unpin_future(fut); // Ошибка: `fut` не реализует типаж `Unpin`
// Закрепление с `Box`:
let fut = async { /* ... */ };
let fut = Box::pin(fut);
execute_unpin_future(fut); // OK
// Закрепление с `pin_mut!`:
let fut = async { /* ... */ };
pin_mut!(fut);
execute_unpin_future(fut); // OK
Резюме
-
Если
T: Unpin(что по умолчанию), тоPin<'a, T>полностью эквивалентен&'a mut T. Другими словами: "Unpin" означает, что этот тип можно перемещать, даже если он закреплён, поэтому "Pin" не повлияет на такой тип. -
Преобразование
&mut Tв закреплённый T требует unsafe, еслиT: !Unpin. -
Большинство типов стандартной библиотеки реализуют
Unpin. То же самое касается большинства "обычных" типов, с которыми вы сталкиваетесь в Rust. ТипFuture, сгенерированный с помощью async/await, является исключением из этого правила. -
Вы можете добавить
!Unpinк типу в nightly версии с помощью флага опции или добавивstd::marker::PhantomPinnedк вашему типу в стабильной версии. -
Вы можете закрепить данные на стеке или на куче.
-
Для закрепления объекта
!Unpinна стеке требуетсяunsafe -
Закрепление объекта
!Unpinна куче не требуетunsafe, для этого есть сокращениеBox::pin. -
Для закреплённых данных, где
T: !Unpin, вы должны поддерживать инвариант, что их память не будет аннулирована или переназначена с момента закрепления до вызова drop. Это важная часть контракта pin.
Типаж Stream
Типаж Stream похож на Future, но до своего завершения может давать несколько значений. Также он похож на типаж Iterator из стандартной библиотеки:
#![allow(unused)] fn main() { trait Stream { /// The type of the value yielded by the stream. type Item; /// Attempt to resolve the next item in the stream. /// Returns `Poll::Pending` if not ready, `Poll::Ready(Some(x))` if a value /// is ready, and `Poll::Ready(None)` if the stream has completed. fn poll_next(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Option<Self::Item>>; } }
Одним из распространённых примеров Stream является Receiver для типа канала из
пакета futures. Он даёт Some(val) каждый раз, когда значение отправляется
от Sender, и даст None после того, как Sender был удалён из памяти и все ожидающие сообщения были получены:
#![allow(unused)] fn main() { async fn send_recv() { const BUFFER_SIZE: usize = 10; let (mut tx, mut rx) = mpsc::channel::<i32>(BUFFER_SIZE); tx.send(1).await.unwrap(); tx.send(2).await.unwrap(); drop(tx); // `StreamExt::next` is similar to `Iterator::next`, but returns a // type that implements `Future<Output = Option<T>>`. assert_eq!(Some(1), rx.next().await); assert_eq!(Some(2), rx.next().await); assert_eq!(None, rx.next().await); } }
Итерирование и параллелизм
Подобно синхронным итераторам, существует множество различных способов итерации
и обработки значений в Stream. Существуют методы комбинаторного стиля
например, map, filter и fold и их братьев раннего-выхода-из-за-ошибки
try_map, try_filter и try_fold.
К сожалению, цикл for не может использоваться для Stream, но для
императивного стиля написания кода, могут быть использованы while let и функции next/try_next:
#![allow(unused)] fn main() { async fn sum_with_next(mut stream: Pin<&mut dyn Stream<Item = i32>>) -> i32 { use futures::stream::StreamExt; // for `next` let mut sum = 0; while let Some(item) = stream.next().await { sum += item; } sum } async fn sum_with_try_next( mut stream: Pin<&mut dyn Stream<Item = Result<i32, io::Error>>>, ) -> Result<i32, io::Error> { use futures::stream::TryStreamExt; // for `try_next` let mut sum = 0; while let Some(item) = stream.try_next().await? { sum += item; } Ok(sum) } }
Однако, если мы просто обрабатываем один элемент за раз, мы потенциально
оставляем возможность для параллелизма, который, в конце концов, стоит на первом месте при написании асинхронного кода. Для обработки нескольких элементов из потока
одновременно, используйте методы for_each_concurrent и try_for_each_concurrent:
#![allow(unused)] fn main() { async fn jump_around( mut stream: Pin<&mut dyn Stream<Item = Result<u8, io::Error>>>, ) -> Result<(), io::Error> { use futures::stream::TryStreamExt; // for `try_for_each_concurrent` const MAX_CONCURRENT_JUMPERS: usize = 100; stream.try_for_each_concurrent(MAX_CONCURRENT_JUMPERS, |num| async move { jump_n_times(num).await?; report_n_jumps(num).await?; Ok(()) }).await?; Ok(()) } }
Одновременное выполнение нескольких Future
До этого времени, мы в основном выполняли футуры используя .await, который блокирует текущую задачу до тех пор, пока не завершится отдельная Future. Однако, настоящие асинхронные приложения чаще всего должны выполнять несколько различных операций одновременно.
В этой главе мы рассмотрим несколько вариантов одновременного выполнения нескольких асинхронных операций:
join!: ждёт завершения всех футурselect!: ждёт завершения одной из футур- Spawning: создаёт высокоуровневые задачи, которые запускают содержащиеся в них футуры до их завершения
FuturesUnordered: группа Future, которые отдают результат каждой SubFuture
join!
Макрос futures::join позволяет дождаться завершения нескольких разных
футур при одновременном их выполнении.
join!
При выполнении нескольких асинхронных операций возникает соблазн просто
последовательно вызвать несколько .await:
#![allow(unused)] fn main() { async fn get_book_and_music() -> (Book, Music) { let book = get_book().await; let music = get_music().await; (book, music) } }
Однако это будет медленнее, чем необходимо, так как он не начнёт пытаться выполнять
get_music до завершения get_book. В некоторых других языках,
футуры выполняются до завершения, поэтому две операции могут быть запущены
одновременно сначала вызовом каждой async fn, для запуска футур, а потом их ожиданием:
#![allow(unused)] fn main() { // WRONG -- don't do this async fn get_book_and_music() -> (Book, Music) { let book_future = get_book(); let music_future = get_music(); (book_future.await, music_future.await) } }
Однако футуры на Rust не будут работать, пока для них не будет вызван .await.
Это означает, что оба приведённых выше фрагмента кода запустят
book_future и music_future последовательно, вместо того, чтобы запустить их
параллельно. Чтобы правильно распараллелить их выполнение, используйте
futures::join!:
#![allow(unused)] fn main() { use futures::join; async fn get_book_and_music() -> (Book, Music) { let book_fut = get_book(); let music_fut = get_music(); join!(book_fut, music_fut) } }
Значение, возвращаемое join! - это кортеж, содержащий выходные данные каждой из переданных Future.
try_join!
Для футур, которые возвращают Result, может использоваться try_join!, а не
join!. Так как join! завершается только после завершения всех подфутур,
он будет продолжать обрабатывать другие футуры даже после того, как одна из подфутур вернёт Err.
В отличие отjoin!, try_join! завершится
немедленно, если какая-либо из подфутур вернёт ошибку.
#![allow(unused)] fn main() { use futures::try_join; async fn get_book() -> Result<Book, String> { /* ... */ Ok(Book) } async fn get_music() -> Result<Music, String> { /* ... */ Ok(Music) } async fn get_book_and_music() -> Result<(Book, Music), String> { let book_fut = get_book(); let music_fut = get_music(); try_join!(book_fut, music_fut) } }
Обратите внимание, что все футуры, переданные в try_join!, должны иметь один и тот же тип ошибки.
Рассмотрите возможность использования функций .map_err(|e| ...) и .err_into() из
futures::future::TryFutureExt для приведения типов ошибок к единому виду:
#![allow(unused)] fn main() { use futures::{ future::TryFutureExt, try_join, }; async fn get_book() -> Result<Book, ()> { /* ... */ Ok(Book) } async fn get_music() -> Result<Music, String> { /* ... */ Ok(Music) } async fn get_book_and_music() -> Result<(Book, Music), String> { let book_fut = get_book().map_err(|()| "Unable to get book".to_string()); let music_fut = get_music(); try_join!(book_fut, music_fut) } }
select!
Макрос futures::select запускает несколько футур
одновременно и передаёт управление пользователю, как только любая из футур завершится.
#![allow(unused)] fn main() { use futures::{ future::FutureExt, // for `.fuse()` pin_mut, select, }; async fn task_one() { /* ... */ } async fn task_two() { /* ... */ } async fn race_tasks() { let t1 = task_one().fuse(); let t2 = task_two().fuse(); pin_mut!(t1, t2); select! { () = t1 => println!("task one completed first"), () = t2 => println!("task two completed first"), } } }
Функция выше запустит обе t1 и t2
параллельно. Когда t1 или t2
закончится, соответствующий дескриптор вызовет
println! и функция завершится без выполнения
оставшейся задачи.
Базовый синтаксис для select: <pattern> = <expression> => <code>,,
повторяемый столько раз, из скольких футур вам надо сделать select.
default => ... и complete => ...
Также select поддерживает ветки default и complete.
Ветка default выполнится, если ни одна из футур,
переданных в select, не завершится. Поэтому
select с веткой default всегда будет
незамедлительно завершаться, так как default будет
запущен, когда ещё ни одна футура не готова.
Ветка complete может быть использована для
обработки случая, когда все футуры, бывшие в
select, завершились и уже не могут прогрессировать. Это бывает удобно, когда select! используется в цикле.
#![allow(unused)] fn main() { use futures::{future, select}; async fn count() { let mut a_fut = future::ready(4); let mut b_fut = future::ready(6); let mut total = 0; loop { select! { a = a_fut => total += a, b = b_fut => total += b, complete => break, default => unreachable!(), // never runs (futures are ready, then complete) }; } assert_eq!(total, 10); } }
Взаимодействие с Unpin и FusedFuture
Одна вещь, на которую вы могли обратить внимание в первом
примере, это то, что мы вызвали .fuse() для футур,
возвращённых из двух async fn, а потом закрепили
их с помощью pin_mut. Оба этих вызова важны,
потому что футуры, используемые в select, должны
реализовывать и типаж Unpin, и типаж
FusedFuture.
Unpin важен по той причине, что футуры, используемые в select, берутся не по значению, а по изменяемой ссылке. Так как владение футурами никому не передано, незавершённые футуры могут быть снова использованы после вызова select.
Аналогично, типаж FusedFuture необходим, так как select не должен опрашивать футуры после их
завершения. FusedFuture реализуется футурами, которые отслеживают, завершены ли они или нет. Это делает
возможным использование select в цикле, опрашивая только те футуры, которые до сих пор не завершились.
Это можно увидеть в примере выше, где a_fut или b_fut будут завершены во второй раз за цикл. Так
как футура, возвращённая future::ready, реализует FusedFuture, она может сообщить
select, что её не надо снова опросить.
Заметьте, что у стримов есть соответствующий типаж FusedStream. Стримы, реализующие этот типаж
или имеющие обёртку, созданную .fuse(), возвращают FusedFuture из комбинаторов
.next() и .try_next().
#![allow(unused)] fn main() { use futures::{ stream::{Stream, StreamExt, FusedStream}, select, }; async fn add_two_streams( mut s1: impl Stream<Item = u8> + FusedStream + Unpin, mut s2: impl Stream<Item = u8> + FusedStream + Unpin, ) -> u8 { let mut total = 0; loop { let item = select! { x = s1.next() => x, x = s2.next() => x, complete => break, }; if let Some(next_num) = item { total += next_num; } } total } }
Распараллеливание задач в цикле с select с помощью Fuse и FuturesUnordered
Одна довольно труднодоступная, но удобная функция - Fuse::terminated(), которая позволяет создавать уже
прекращённые пустые футуры, которые в последствии могут быть заполнены другой футурой, которую надо запустить.
Это может быть удобно, когда есть задача, которую надо запустить в цикле в select, но которая
создана вне этого цикла.
Обратите внимание на функцию .select_next_some(). Она может использоваться с select для запуска полученных из стрима тех
ветвей, которые имеют значение Some(_), а не None.
#![allow(unused)] fn main() { use futures::{ future::{Fuse, FusedFuture, FutureExt}, stream::{FusedStream, Stream, StreamExt}, pin_mut, select, }; async fn get_new_num() -> u8 { /* ... */ 5 } async fn run_on_new_num(_: u8) { /* ... */ } async fn run_loop( mut interval_timer: impl Stream<Item = ()> + FusedStream + Unpin, starting_num: u8, ) { let run_on_new_num_fut = run_on_new_num(starting_num).fuse(); let get_new_num_fut = Fuse::terminated(); pin_mut!(run_on_new_num_fut, get_new_num_fut); loop { select! { () = interval_timer.select_next_some() => { // The timer has elapsed. Start a new `get_new_num_fut` // if one was not already running. if get_new_num_fut.is_terminated() { get_new_num_fut.set(get_new_num().fuse()); } }, new_num = get_new_num_fut => { // A new number has arrived -- start a new `run_on_new_num_fut`, // dropping the old one. run_on_new_num_fut.set(run_on_new_num(new_num).fuse()); }, // Run the `run_on_new_num_fut` () = run_on_new_num_fut => {}, // panic if everything completed, since the `interval_timer` should // keep yielding values indefinitely. complete => panic!("`interval_timer` completed unexpectedly"), } } } }
Когда надо одновременно запустить много копий какой-либо футуры, используйте тип FuturesUnordered.
Следующий пример похож на один из тех, что был выше, но здесь мы дожидаемся завершения каждой выполненной копии
run_on_new_num_fut, а не останавливаем её при создании новой. Он также отобразит значение, возвращённое
run_on_new_num_fut.
#![allow(unused)] fn main() { use futures::{ future::{Fuse, FusedFuture, FutureExt}, stream::{FusedStream, FuturesUnordered, Stream, StreamExt}, pin_mut, select, }; async fn get_new_num() -> u8 { /* ... */ 5 } async fn run_on_new_num(_: u8) -> u8 { /* ... */ 5 } async fn run_loop( mut interval_timer: impl Stream<Item = ()> + FusedStream + Unpin, starting_num: u8, ) { let mut run_on_new_num_futs = FuturesUnordered::new(); run_on_new_num_futs.push(run_on_new_num(starting_num)); let get_new_num_fut = Fuse::terminated(); pin_mut!(get_new_num_fut); loop { select! { () = interval_timer.select_next_some() => { // The timer has elapsed. Start a new `get_new_num_fut` // if one was not already running. if get_new_num_fut.is_terminated() { get_new_num_fut.set(get_new_num().fuse()); } }, new_num = get_new_num_fut => { // A new number has arrived -- start a new `run_on_new_num_fut`. run_on_new_num_futs.push(run_on_new_num(new_num)); }, // Run the `run_on_new_num_futs` and check if any have completed res = run_on_new_num_futs.select_next_some() => { println!("run_on_new_num_fut returned {:?}", res); }, // panic if everything completed, since the `interval_timer` should // keep yielding values indefinitely. complete => panic!("`interval_timer` completed unexpectedly"), } } } }
Обходные пути, которые мы понимаем и любим
Поддержка async в Rust всё ещё довольно нова и
некоторые востребованные функции активно разрабатываются, а
некоторые диагностики до сих пор не полноценны. В этой главе
обсуждаются некоторые болевые точки и объясняется как с ними
работать.
? в async блоках
Как и в async fn, ? также может
использоваться внутри async блоков. Однако
возвращаемый тип async блоков явно не
указывается. Это может привести тому, что компилятор не сможет
определить тип ошибки async блока.
Например, этот код:
#![allow(unused)] fn main() { let fut = async { foo().await?; bar().await?; Ok(()) }; }
вызовет ошибку:
error[E0282]: type annotations needed
--> src/main.rs:5:9
|
4 | let fut = async {
| --- consider giving `fut` a type
5 | foo().await?;
| ^^^^^^^^^^^^ cannot infer type
К сожалению, сейчас не способа "задать тип для fut"
кроме как явно указать возвращаемый тип async
блока. Для обработки этого, используйте "turbofish" оператор для
предоставления типов ошибки и успеха async блока:
#![allow(unused)] fn main() { let fut = async { foo().await?; bar().await?; Ok::<(), MyError>(()) // <- обратите внимание на явное указание типа }; }
Send Approximation
Некоторые машины состояний асинхронных функций безопасны
для передачи между потокам, в то время как другие - нет. Так или
иначе, async fn Future является
Send если тип, содержащийся в
.await, тоже Send. Компилятор
делает всё возможное, чтобы при близиться к моменту, когда
значения могут удерживаться в .await, но сейчас в
некоторых местах этот анализ слишком консервативен.
Например, рассмотрим простой не-Send тип,
например, содержащий Rc:
#![allow(unused)] fn main() { use std::rc::Rc; #[derive(Default)] struct NotSend(Rc<()>); }
Переменные типа NotSend могут появляться как
временные внутри async fn даже когда тип Future,
возвращаемой из async fn должен быть
Send:
async fn bar() {} async fn foo() { NotSend::default(); bar().await; } fn require_send(_: impl Send) {} fn main() { require_send(foo()); }
Но если мы изменим foo таким образом, что она
будет хранить NotSend в переменной, пример не
скомпилируется:
#![allow(unused)] fn main() { async fn foo() { let x = NotSend::default(); bar().await; } }
error[E0277]: `std::rc::Rc<()>` cannot be sent between threads safely
--> src/main.rs:15:5
|
15 | require_send(foo());
| ^^^^^^^^^^^^ `std::rc::Rc<()>` cannot be sent between threads safely
|
= help: within `impl std::future::Future`, the trait `std::marker::Send` is not implemented for `std::rc::Rc<()>`
= note: required because it appears within the type `NotSend`
= note: required because it appears within the type `{NotSend, impl std::future::Future, ()}`
= note: required because it appears within the type `[static generator@src/main.rs:7:16: 10:2 {NotSend, impl std::future::Future, ()}]`
= note: required because it appears within the type `std::future::GenFuture<[static generator@src/main.rs:7:16: 10:2 {NotSend, impl std::future::Future, ()}]>`
= note: required because it appears within the type `impl std::future::Future`
= note: required because it appears within the type `impl std::future::Future`
note: required by `require_send`
--> src/main.rs:12:1
|
12 | fn require_send(_: impl Send) {}
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
error: aborting due to previous error
For more information about this error, try `rustc --explain E0277`.
Эта ошибка корректна. Если мы сохраним x в
переменную, она не будет удалена пока не будет завершён
.await. В этот момент async fn может
быть запущена в другом потоке. Так как Rc не
является Send, перемещение между потоками будет
некорректным. Простым решением будет вызов
drop у Rc до вызова
.await, но к сожалению пока что это не работает.
Для того, чтобы успешно обойти эту проблему, вы можете создать
блок, инкапсулирующий любые не-Send
переменные. С помощью этого, компилятору будет проще понять,
что такие переменные не переживут момент вызова
.await.
#![allow(unused)] fn main() { async fn foo() { { let x = NotSend::default(); } bar().await; } }
Рекурсия
Под капотом, async fn создаёт тип конечного автомата, содержащий каждую подфутуру
для который был вызван .await. Из-за этого
рекурсивные async fn становятся более сложными,
так как итоговый конечный автомат содержит сам себя:
#![allow(unused)] fn main() { // Эта функция: async fn foo() { step_one().await; step_two().await; } // создаёт типы, подобные следующим: enum Foo { First(StepOne), Second(StepTwo), } // А эта функция: async fn recursive() { recursive().await; recursive().await; } // создаёт такие типы: enum Recursive { First(Recursive), Second(Recursive), } }
Это не будет работать - мы создали тип бесконечного размера! Компилятор будет жаловаться:
error[E0733]: recursion in an `async fn` requires boxing
--> src/lib.rs:1:22
|
1 | async fn recursive() {
| ^ an `async fn` cannot invoke itself directly
|
= note: a recursive `async fn` must be rewritten to return a boxed future.
Чтобы исправить это, мы должны ввести косвенность при помощи
Box. К сожалению, из-за ограничений компилятора,
обернуть вызов recursive() в Box::pin
не достаточно. Чтобы это заработало, мы должны сделать
recursive не асинхронной функцией, которая
возвращает .boxed() с async блоком:
#![allow(unused)] fn main() { use futures::future::{BoxFuture, FutureExt}; fn recursive() -> BoxFuture<'static, ()> { async move { recursive().await; recursive().await; }.boxed() } }
async в типажах
В настоящий момент async fn не могут
использоваться в типажах. Причиной является большая сложность,
но снятие этого ограничения находится в планах на будущее.
Однако вы можете обойти это ограничение при помощи пакета async_trait с crates.io.
Заметьте, что использование этих методов типажей приведёт к выделениям памяти в куче для каждого вызова функции. Это не значительная стоимость для большинства приложений, но следует это учитывать при принятии решения использовать данную функциональность в публичном API низкоуровневых функций, которые будут вызываться миллион раз в секунду.
Асинхронная экосистема
На данный момент Rust предоставляет только самое необходимое для написание асинхронного кода. Важно отметить, что исполнители, задачи, реакторы, комбинаторы и низкоуровневая I/O функциональность не предоставляется стандартной библиотекой. Но асинхронные экосистемы, предоставляемые сообществом, восполняют эти пробелы.
Команда Async Foundations заинтересована в расширении примеров в Async Book для охвата нескольких сред выполнения. Если вы хотите внести свой вклад в этот проект, свяжитесь с нами через Zulip .
Асинхронные среды выполнения
Асинхронные среды выполнения — это библиотеки, используемые для выполнения асинхронных приложений. Среды выполнения обычно объединяют реактор с одним или несколькими исполнителями. Реакторы предоставляют механизмы подписки на внешние события, такие как асинхронный ввод-вывод, межпроцессное взаимодействие и таймеры. В асинхронной среде выполнения подписчиками обычно являются футуры, представляющие низкоуровневые операции ввода-вывода. Исполнители занимаются планированием и выполнением задач. Они отслеживают запущенные и приостановленные задачи, опрашивают футуры до завершения и пробуждают задачи, когда они могут продвигаться вперёд. Слово «исполнитель» часто используется как синоним «среды выполнения». Здесь мы используем слово «экосистема» для описания среды выполнения с совместимыми чертами и функциями.
Предоставленные сообществом асинхронные крейты
Крейт Futures
Крейт futures содержит трейты и функции, полезные для написания асинхронного кода. Сюда входят трейты Stream, Sink , AsyncRead и AsyncWrite, а также такие утилиты, как комбинаторы. Эти утилиты и трейты со временем могут стать частью стандартной библиотеки.
У futures есть собственный исполнитель, но нет собственного реактора, поэтому он не поддерживает выполнение асинхронного ввода-вывода или футур по таймеру. По этой причине он не считается полной средой выполнения. Обычная практика — использовать утилиты из futures с исполнителем из другого крейта.
Популярные асинхронные среды выполнения
В стандартной библиотеке нет асинхронной среды выполнения, и ни одна из них официально не рекомендована. Следующие крейты содержат популярные среды выполнения.
- Tokio: популярная асинхронная экосистема с HTTP, gRPC и платформами отслеживания.
- async-std: крейт, предоставляющий асинхронные аналоги компонентов стандартной библиотеки.
- smol: небольшая упрощённая асинхронная среда выполнения. Предоставляет
Async, который можно использовать обёртки таких структур, какUnixStreamилиTcpListener. - fuchsia-async: исполнитель для использования в ОС Fuchsia.
Определение совместимости экосистем
Не все асинхронные приложения, платформы и библиотеки совместимы друг с другом или с каждой ОС или платформой. Большую часть асинхронного кода можно использовать с любой экосистемой, но некоторые Фреймворки и библиотеки требуют использования определённой экосистемы. Ограничения экосистемы не всегда документируются, но есть несколько эмпирических правил, позволяющих определить, зависит ли библиотека, трейт или функция от конкретной экосистемы.
Любой асинхронный код, взаимодействующий с асинхронным вводом-выводом, таймерами, межпроцессным взаимодействием или задачами, обычно зависит от конкретного асинхронного исполнителя или реактора. Весь другой асинхронный код, такой как асинхронные выражения, комбинаторы, типы синхронизации и потоки, обычно не зависит от экосистемы, при условии, что внутренние футуры также не зависят от экосистемы. Перед началом проекта рекомендуется изучить соответствующие асинхронные платформы и библиотеки, чтобы обеспечить совместимость с выбранной вами средой выполнения и друг с другом.
Примечательно, что Tokio использует реактор mio и определяет свои собственные версии трейтов асинхронного ввода-вывода, включая AsyncRead и AsyncWrite. Сам по себе он не совместим с async-std и smol, которые полагаются на крейт async-executor, а также на AsyncRead и AsyncWrite, определённые в futures.
Конфликты зависимостей иногда можно разрешить с помощью прослойки, которая позволит вызывать код для одной среды выполнения из другой. Например, async_compat обеспечивает прослойку между Tokio и другими средами выполнения.
Библиотеки, предоставляющие асинхронные API, не должны зависеть от конкретного исполнителя или реактора, если только им не нужно порождать задачи или определять свои собственные асинхронные операции ввода-вывода или таймеры. В идеале только двоичные файлы должны отвечать за планирование и выполнение задач.
Однопоточные и многопоточные исполнители
Асинхронные исполнители могут быть однопоточными или многопоточными. Например, крейт async-executor имеет как однопоточный LocalExecutor, так и многопоточный Executor .
Многопоточный исполнитель выполняет несколько задач одновременно. Это может значительно ускорить выполнение с множеством задач, но синхронизация данных между задачами обычно обходится довольно дорого. При выборе между однопоточной и многопоточной средой выполнения рекомендуется измерять производительность вашего приложения.
Задачи могут выполняться в текущем потоке либо в отдельном. Асинхронные среды выполнения часто предоставляют возможность запуска задач в отдельном потоке, но даже тогда задачи всё равно должны быть неблокирующими. Чтобы задачи были выполнены на многопоточном исполнителе, они должны реализовывать типаж Send. Некоторые среды выполнения позволяют порождать задачи без Send, что гарантирует выполнение каждой задачи в потоке, который её породил. Они также могут предоставлять функции для порождения блокирующих задач в отдельных потоках, что полезно для запуска блокирующего синхронного кода из других библиотек.
Финальный проект: Создание конкурентного веб-сервера с асинхронным Rust
В этой главе мы будем использовать асинхронный Rust для модификации однопоточного веб-сервера из книги Rust для одновременного обслуживания запросов.
Резюме
Вот как выглядел код в конце урока.
src/main.rs:
use std::fs; use std::io::prelude::*; use std::net::TcpListener; use std::net::TcpStream; fn main() { // Listen for incoming TCP connections on localhost port 7878 let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); // Block forever, handling each request that arrives at this IP address for stream in listener.incoming() { let stream = stream.unwrap(); handle_connection(stream); } } fn handle_connection(mut stream: TcpStream) { // Read the first 1024 bytes of data from the stream let mut buffer = [0; 1024]; stream.read(&mut buffer).unwrap(); let get = b"GET / HTTP/1.1\r\n"; // Respond with greetings or a 404, // depending on the data in the request let (status_line, filename) = if buffer.starts_with(get) { ("HTTP/1.1 200 OK\r\n\r\n", "hello.html") } else { ("HTTP/1.1 404 NOT FOUND\r\n\r\n", "404.html") }; let contents = fs::read_to_string(filename).unwrap(); // Write response back to the stream, // and flush the stream to ensure the response is sent back to the client let response = format!("{}{}", status_line, contents); stream.write(response.as_bytes()).unwrap(); stream.flush().unwrap(); }
hello.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hello!</title>
</head>
<body>
<h1>Hello!</h1>
<p>Hi from Rust</p>
</body>
</html>
404.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hello!</title>
</head>
<body>
<h1>Oops!</h1>
<p>Sorry, I don't know what you're asking for.</p>
</body>
</html>
Если вы запустите сервер с помощью cargo run и посетите 127.0.0.1:7878 в своём браузере, вас встретит дружеское сообщение от Ferris!
Запуск асинхронного кода
HTTP-сервер должен иметь возможность обслуживать несколько клиентов одновременно, не дожидаясь завершения предыдущих запросов перед обработкой текущего запроса. В книге эта проблема решается путём создания пула потоков, в котором каждое соединение обрабатывается в отдельном потоке. Здесь вместо повышения пропускной способности за счёт добавления потоков мы добьёмся того же эффекта, используя асинхронный код.
Давайте изменим handle_connection, чтобы он возвращал футуру, объявив его async fn:
async fn handle_connection(mut stream: TcpStream) {
//<-- snip -->
}
Добавление async к объявлению функции меняет тип возвращаемого значения с unit type () на тип, который реализует Future<Output=()>.
Если мы попытаемся скомпилировать это, компилятор предупредит нас, что это не сработает:
$ cargo check
Checking async-rust v0.1.0 (file:///projects/async-rust)
warning: unused implementer of `std::future::Future` that must be used
--> src/main.rs:12:9
|
12 | handle_connection(stream);
| ^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: `#[warn(unused_must_use)]` on by default
= note: futures do nothing unless you `.await` or poll them
Поскольку мы не сделали await или poll функции handle_connection, то она никогда не запустится. Если вы запустите сервер и зайдёте на 127.0.0.1:7878 в браузере, то увидите, что в соединении отказано, наш сервер не обрабатывает запросы.
Мы не можем выполнить await или poll футуры в синхронном коде, как если бы это был вызов обычной функции. Нам понадобится асинхронная среда выполнения для планирования и выполнения футур. Обратитесь к разделу о выборе среды выполнения для получения дополнительной информации об асинхронных средах выполнения, исполнителях и реакторах. Для этого проекта подойдёт любая из перечисленных сред выполнения, но для этих примеров мы решили использовать крейт async-std.
Добавление асинхронной среды выполнения
В следующем примере демонстрируется рефакторинг синхронного кода в асинхронный, мы используем async-std. #[async_std::main] из async-std позволяет нам написать асинхронную основную функцию. Чтобы использовать его, включите опцию attributes для async-std в Cargo.toml :
[dependencies.async-std]
version = "1.6"
features = ["attributes"]
В качестве первого шага мы переключимся на асинхронную основную функцию и будем ожидать (await) футуры, возвращаемой асинхронной версией handle_connection. Затем мы проверим, как сервер отвечает. Вот как это будет выглядеть:
#[async_std::main] async fn main() { let listener = TcpListener::bind("127.0.0.1:7878").unwrap(); for stream in listener.incoming() { let stream = stream.unwrap(); // Warning: This is not concurrent! handle_connection(stream).await; } }
Теперь давайте проверим, может ли наш сервер одновременно обрабатывать соединения. Сделать handle_connection асинхронным не достаточно, чтобы сервер мог обрабатывать несколько подключений одновременно, и скоро мы увидим почему.
Чтобы проиллюстрировать это, давайте смоделируем медленный запрос. Когда клиент делает запрос к 127.0.0.1:7878/sleep , наш сервер будет спать в течение 5 секунд:
use std::time::Duration;
use async_std::task;
async fn handle_connection(mut stream: TcpStream) {
let mut buffer = [0; 1024];
stream.read(&mut buffer).unwrap();
let get = b"GET / HTTP/1.1\r\n";
let sleep = b"GET /sleep HTTP/1.1\r\n";
let (status_line, filename) = if buffer.starts_with(get) {
("HTTP/1.1 200 OK\r\n\r\n", "hello.html")
} else if buffer.starts_with(sleep) {
task::sleep(Duration::from_secs(5)).await;
("HTTP/1.1 200 OK\r\n\r\n", "hello.html")
} else {
("HTTP/1.1 404 NOT FOUND\r\n\r\n", "404.html")
};
let contents = fs::read_to_string(filename).unwrap();
let response = format!("{status_line}{contents}");
stream.write(response.as_bytes()).unwrap();
stream.flush().unwrap();
}
Это очень похоже на симуляцию медленного запроса из Книги, но с одним важным отличием: мы используем неблокирующую функцию async_std::task::sleep вместо блокирующей std::thread::sleep. Важно помнить, что даже если функция асинхронная (async fn) и будет ожидать выполнения (await), она все равно может быть блокирующей. Чтобы проверить, обрабатывает ли наш сервер соединения одновременно, нам нужно убедиться, что handle_connection неблокирующая.
Если вы запустите сервер, то увидите, что запрос на 127.0.0.1:7878/sleep блокирует любые другие входящие запросы на 5 секунд! Это связано с тем, что другие конкурентные задачи не могут выполняться, пока мы ожидаем (await) результата handle_connection. В следующем разделе мы увидим, как использовать асинхронный код для одновременной обработки подключений.
Конкурентная обработка подключений
Проблема с нашим кодом на данный момент заключается в том, что listener.incoming() является блокирующим итератором. Исполнитель не может запускать другие футуры, пока listener ожидает входящих соединений, и мы не можем обрабатывать новое соединение, пока не закончим с предыдущим.
Чтобы исправить это, мы преобразуем listener.incoming() из блокирующего Iterator в неблокирующий Stream. Потоки похожи на итераторы, но могут использоваться асинхронно. Для получения дополнительной информации см. главу о потоках .
Давайте заменим наш блокирующий std::net::TcpListener на неблокирующий async_std::net::TcpListener и обновим наш обработчик соединения, чтобы он принимал async_std::net::TcpStream:
use async_std::prelude::*;
async fn handle_connection(mut stream: TcpStream) {
let mut buffer = [0; 1024];
stream.read(&mut buffer).await.unwrap();
//<-- snip -->
stream.write(response.as_bytes()).await.unwrap();
stream.flush().await.unwrap();
}
Асинхронная версия TcpListener реализует трейт Stream для listener.incoming(), это изменение даёт два преимущества. Во-первых, listener.incoming() больше не блокирует исполнителя. Теперь исполнитель может перейти к другим ожидающим футурам, пока нет входящих TCP-соединений для обработки.
Второе преимущество заключается в том, что элементы из Stream могут обрабатываться конкурентно с помощью метода for_each_concurrent. Здесь мы воспользуемся этим методом для конкурентной обработки каждого входящего запроса. Нам нужно импортировать трейт Stream из крейта futures, поэтому наш Cargo.toml теперь выглядит так:
+[dependencies]
+futures = "0.3"
[dependencies.async-std]
version = "1.6"
features = ["attributes"]
Теперь мы можем обрабатывать каждое соединение конкурентно, передавая handle_connection через замыкание. Замыкание становится владельцем каждого TcpStream и запускается, как только становится доступным новый TcpStream. Поскольку handle_connection не блокирующий, медленный запрос больше не будет препятствовать выполнению других запросов.
use async_std::net::TcpListener;
use async_std::net::TcpStream;
use futures::stream::StreamExt;
#[async_std::main]
async fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").await.unwrap();
listener
.incoming()
.for_each_concurrent(/* limit */ None, |tcpstream| async move {
let tcpstream = tcpstream.unwrap();
handle_connection(tcpstream).await;
})
.await;
}
Параллельное обслуживание запросов
В нашем примере до сих пор конкурентность (с использованием асинхронного кода) в основном представлялась как альтернатива параллелизму (с использованием потоков). Однако асинхронный код и потоки не исключают друг друга. В нашем примере for_each_concurrent обрабатывает каждое соединение, но в одном потоке. async-std также позволяет нам запускать задачи в отдельных потоках. Поскольку handle_connection является Send и неблокирующий, его безопасно использовать с async_std::task::spawn. Вот как это будет выглядеть:
use async_std::task::spawn; #[async_std::main] async fn main() { let listener = TcpListener::bind("127.0.0.1:7878").await.unwrap(); listener .incoming() .for_each_concurrent(/* limit */ None, |stream| async move { let stream = stream.unwrap(); spawn(handle_connection(stream)); }) .await; }
Теперь мы используем конкурентность и параллелизм для одновременной обработки нескольких запросов! Дополнительную информацию см. в разделе о многопоточных исполнителях.
Тестирование TCP-сервера
Давайте перейдём к тестированию нашей функции handle_connection.
Во-первых, нам нужен TcpStream для работы. В сквозном или интеграционном тесте мы можем захотеть установить реальное TCP-соединение для проверки нашего кода. Одна из стратегий для этого — запустить приложение на порту 0 localhost. Порт 0 не является допустимым портом UNIX, но он подойдёт для тестирования. Операционная система выберет для нас открытый порт TCP.
Вместо этого в этом примере мы напишем модульный тест для обработчика соединения, чтобы проверить, что для входных данных возвращаются правильные ответы. Чтобы наш модульный тест оставался изолированным и детерминированным, мы замокаем TcpStream.
Для начала, мы изменим сигнатуру handle_connection, чтобы упростить тестирование. handle_connection на самом деле не требует async_std::net::TcpStream, а требует любую структуру, которая реализует async_std::io::Read, async_std::io::Write и marker::Unpin. Изменив сигнатуру типа таким образом, мы сможем передать мок для тестирования.
use async_std::io::{Read, Write};
async fn handle_connection(mut stream: impl Read + Write + Unpin) {
Далее давайте создадим мок TcpStream, который реализует нужные типажи. Во-первых, давайте реализуем типаж Read с методом poll_read. Наш мок TcpStream будет содержать некоторые данные, которые копируются в буфер чтения, и мы вернём Poll::Ready, чтобы показать, что чтение завершено.
use super::*;
use futures::io::Error;
use futures::task::{Context, Poll};
use std::cmp::min;
use std::pin::Pin;
struct MockTcpStream {
read_data: Vec<u8>,
write_data: Vec<u8>,
}
impl Read for MockTcpStream {
fn poll_read(
self: Pin<&mut Self>,
_: &mut Context,
buf: &mut [u8],
) -> Poll<Result<usize, Error>> {
let size: usize = min(self.read_data.len(), buf.len());
buf[..size].copy_from_slice(&self.read_data[..size]);
Poll::Ready(Ok(size))
}
}
Наша реализация Write очень похожа, хотя нам нужно написать три метода: poll_write, poll_flush и poll_close. poll_write скопирует входные данные в мок TcpStream и вернёт Poll::Ready после завершения. Для сброса или закрытия мока TcpStream не требуется никакой работы, поэтому poll_flush и poll_close могут просто вернуть Poll::Ready .
impl Write for MockTcpStream {
fn poll_write(
mut self: Pin<&mut Self>,
_: &mut Context,
buf: &[u8],
) -> Poll<Result<usize, Error>> {
self.write_data = Vec::from(buf);
Poll::Ready(Ok(buf.len()))
}
fn poll_flush(self: Pin<&mut Self>, _: &mut Context) -> Poll<Result<(), Error>> {
Poll::Ready(Ok(()))
}
fn poll_close(self: Pin<&mut Self>, _: &mut Context) -> Poll<Result<(), Error>> {
Poll::Ready(Ok(()))
}
}
Наконец, нашему моку нужно будет реализовать Unpin, что означает, что его местоположение в памяти может быть безопасно перемещено. Для получения дополнительной информации о закреплении и Unpin см. раздел о закреплении .
impl Unpin for MockTcpStream {}
Теперь мы готовы протестировать функцию handle_connection. После настройки MockTcpStream, содержащего некоторые начальные данные, мы можем запустить handle_connection, используя атрибут #[async_std::test], аналогично тому, как мы использовали #[async_std::main]. Чтобы убедиться, что handle_connection работает должным образом, мы проверим, что в MockTcpStream были записаны правильные данные на основе его исходного содержимого.
use std::fs;
#[async_std::test]
async fn test_handle_connection() {
let input_bytes = b"GET / HTTP/1.1\r\n";
let mut contents = vec![0u8; 1024];
contents[..input_bytes.len()].clone_from_slice(input_bytes);
let mut stream = MockTcpStream {
read_data: contents,
write_data: Vec::new(),
};
handle_connection(&mut stream).await;
let expected_contents = fs::read_to_string("hello.html").unwrap();
let expected_response = format!("HTTP/1.1 200 OK\r\n\r\n{}", expected_contents);
assert!(stream.write_data.starts_with(expected_response.as_bytes()));
}
Приложение: Переводы книги
Ресурсы на языках, отличных от английского.